طراحی و پیاده سازی دیتاسنتر
ویژگی های FAST VP
در قسمت دوم مقاله های FAST VP می خواهیم ویژگی های FAST VP را مورد بحث و بررسی قرار دهیم ؛ که در ادامه به آن می پردازیم.
POOL ها
Pool مجموعه ای از درایو ها است که LUN ها در آن ایجاد می شوند. Pool ها را بر روی تمامی سیستم های EMC Unity، از جمله خانواده Unity A
ll Flash ، خانواده Unity Hybrid یا UnityVSA می توان ایجاد کرد. در سیستم های Unity All Flash و Hybrid، این Pool ها شامل درایوهای فیزیکی موجود روی دستگاه هستند. Pool ها در UnityVSA ، بر روی دیسک هایی مجازی ایجاد شده اند که فضای آن ها توسط هاست VMWare ESXi تامین می گردد و UnityVSA از آن بهره می برد. Pool ها می توانند شامل تعداد کمی از درایو ها و یا تمام درایو ها در یک سیستم باشند. FAST VP یک ویژگی نرم افزاری است که به طور موثری به بهره وری از منابع موجود در یک Pool کمک می کند. یک Pool می تواند حاوی یک نوع درایو یا ترکیبی از انواع درایوها باشد.
یک Pool که تنها شامل یک نوع درایو است، Single Tier pool نامیده می شود، همچنین با نامِ Homogenous Pool شناخته می شود. Single Tier pool می تواند شامل تمام درایوهای Flash، درایوهای SAS یا تمام درایوهای NL-SAS باشد. از آنجایی که همه درایوهای داخل Pool از یک نوع هستند، Single Tier poolها عملکرد پیش بینی شده ای را می توانند ارائه دهند. تمام داده های موجود در یک Single Tier pool ، صرف نظر از بازه زمانی ایجاد داده ، پتانسیل عملکرد یکسانی دارند. هنگامی که دسترسی داده در سراسر یک محدوده آدرس دهی بزرگ یکنواخت باشد Single Tier Pools بهترین بهره وری را داراست.
یک Pool که حاوی مخلوطی از انواع درایوها است، multi-tiered Pool نامیده می شود که همچنین به عنوان Hybrid Pool یا Heterogeneous Pool شناخته می شود. multi-tiered Pool می تواند هر ترکیبی از Flash، SAS و NL-SAS را در اختیار داشته باشد. به عنوان مثال، یک Pool ممکن است حاوی هر سه نوع درایو باشد، یا فقط شامل درایوهای Flash و NL-SAS یا تنها درایوهای SAS و NL-SAS باشد. در multi-tiered Pool ، داده های موجود در منابع ذخیره سازی توسط FAST VP در Slice هایی 256 مگابایتی در سراسر Tier ها پخش می شوند. FAST VP بر استفاده از هر Tier نظارت می کند و Slice های داده ی درون Pool را بر اساس درجه حرارت Slice ها و ظرفیتشان مکان بندی می کند.
انواع Tier ها در Fast VP
هنگامی که یک Pool ایجاد می شود، هر نوع درایو درون Pool به یک Tier خاص اختصاص داده می شود. هر Tier سطح عملکردی متفاوت را با توجه به نوع درایو و تعداد درایو های موجود در Tier ارائه می دهد. همچنین هر Tier در یک Pool می تواند ظرفیت ذخیره سازی متفاوتی داشته باشد، در نتیجه به شما این امکان را می دهد تا میزان ذخیره سازی هر نوع درایوِ تخصیص یافته به pool را تنظیم نمایید. FAST VP درایوها را به سه سطح تقسیم می کند. این سطوح عبارتند از:
- Extreme Performance Tier – شامل درایوهای Flash است
- Performance Tier – شامل درایوهای (Serial Attached SCSI (SAS است
- Capacity Tier – شامل درایوهای (Near-Line SAS (NL-SAS
FAST VP هر کدام از این Tier ها را بر اساس نوع درایو، و نه سرعت چرخش تفکیک می کند. EMC پیشنهاد می کند درایو های با سرعت چرخش مختلف از یک Tier را در یک Pool با هم ترکیب نکنید. به عنوان مثال، درایوهای 10K RPM و 15K RPM SAS را در یک Pool ترکیب نکنید. همچنین توصیه می شود این درایو ها را به Pool های مختلف اختصاص دهید. لازم به ذکر است که اگر درایوهای 10K RPM SAS در یک Pool با درایوهای 7.2K RPM NL-SAS ترکیب شوند، مشکلی پیش نخواهد آمد زیرا آنها درایوهایی از انواع متفاوت هستند و در Tier های مختلفی قرار دارند.
FAST VP تمام Tier ها را در یک Pool به کار می برد، چرا که هر Tier مزایای منحصر به فردی در رابطه با عملکرد و هزینه ها ارائه می دهند.
تنظیمات POOL TIER RAID
هنگام ایجاد یک Pool، می توانید انوع مختلف RAID را برای هر یک از Tier ها تنظیم نمایید. هنگامی که یک RAID برای هر Tier انتخاب و Pool ایجاد شده است، RAID را نمی توان تغییر داد. به هنگام گسترش یک Pool برای افزودن یک نوع درایو جدید، می توانید RAID را انتخاب کنید. جدول زیر انواع تنظیمات RAID را نشان می دهد که برای هر Tier پشتیبانی می شوند. در جدول زیر انواع پیکربندی درایوها در RAID آورده شده است.
تنظیمات POOL TIER RAID
هنگام تصمیم گیری در مورد استفاده از پیکربندی RAID، عملکرد، ظرفیت و سطوح حفاظت هر پیکربندی را در نظر بگیرید. RAID 1/0 برای برنامه های کاربردی با مقادیر زیادی از نوشته های تصادفی پیشنهاد می شود، زیرا هیچ parity نوشتنی در این نوع RAID وجود ندارد. هنگامی که نگرانی در مورد هزینه و عملکرد وجود داشته باشد RAID 5 ترجیح داده می شود. RAID 6 بیشترین میزان حفاظت از داده ها در برابر خرابی درایو ها را دارا است. اما باید در نظر داشت که به هنگامِ استفاده از تنظیمات RAID با تعداد درایوهای زیاد (12+1 , 12+2 , 14+2) در مولفه هایی مانند زمان Rebuild کردن درایوها و در هنگام خطا با چالش هایی نظیر افت عملکرد و تاخیر رو به رو خواهیم بود.
EXTREME PERFORMANCE TIER
Extreme Performance Tier در اغلب موارد برای ذخیره سازی اطلاعاتی استفاده می شود که به زمان پاسخ حساس هستند و نیاز به یک سطح بالایی از عملکرد دارند. درایوهای Flash در Extreme Performance Tier به کار رفته اند زیرا دارای Latency کمی هستند.
هنگام ایجاد یک Pool پیشنهاد می شود که درایوهای Flash را به پیکربندی اضافه کنید. حتی یک مقدار کم از ظرفیت Flash اضافه شده به Pool می تواند توسط FAST VP برای افزایش عملکرد کلی سیستم مورد استفاده قرار گیرد. برای بهترین سرمایه گذاری، از درایوهای Flash برای ذخیره hot data روی منابع ذخیره سازی ای که نیاز به زمان پاسخ سریع و IOPs بالا دارند، استفاده کنید. FAST VP منابع کل Pool را بهینه سازی می کند و در صورت نیاز داده هایی را که کمتر فعال هستند، به طور خودکار به سطوح دیگر انتقال می دهد.
Extreme Performance Tier را می توان با استفاده از درایوهای فلش SAS Flash 2، SAS Flash 3 یا SAS Flash 4 ایجاد کرد. در حالی که توصیه نمی شود درایو های SAS Flash مختلف را در همان Pool ترکیب کنید. در Unity OE نسخه 4.1 و بالاتر، درایوهای SAS Flash 3 می توانند در Hybrid Pools (mixed drive type) استفاده شوند. درایوهای SAS Flash 4 فقط در سیستم Unity All-Flash پشتیبانی می شوند.
PERFORMANCE TIER
Performance Tier عملکرد بالا و همه جانبه ای را از طریق ارائه زمان پاسخ سازگار، I/O بالا و پهنای باند خوب در کنار قیمتی متوسط فراهم می کند. Performance Tier شامل درایوهای SAS است که سطح بالایی از عملکرد، قابلیت اطمینان و ظرفیت را ارائه می دهند. تکنولوژی درایوهای SAS مبتنی بر تکنولوژی چرخش مکانیکی سخت افزاری است که از پلاترهای مغناطیسی برای ذخیره داده ها استفاده می کند. Performance Tier را می توان با استفاده از درایوهای 15K RPM یا 10K RPM SAS ایجاد کرد. اگر چه چنین چیزی امکان پذیر است اما ترکیبِ درایوهای SAS با سرعت های مختلف، در یک Pool پیشنهاد نمی شود.
CAPACITY TIER
Capacity Tier یک Tier از محدوده ظرفیت ذخیره سازی در یک Pool است که شامل درایو های 7.2K RPM NL-SAS با ظرفیت بسیار و هزینه کم می شود. Capacity Tier با استفاده از درایوهای NL-SAS، به کاهش هزینه در هر GB از Pool کمک می کند. Capacity Tier موجود در FAST VP برای ذخیره داده هایی است که عمدتا استاتیک هستند و اغلب در دسترس نیستند. این بهترین راه برای استفاده ار داده هایی است که کاربرد زیادی ندارند. در نتیجه داده هایی که سطح فعالیت کمتری نسبت به بقیه دارند و به اصطلاح به آن ها cold data می گوییم در دسته سوم Tier بندی یعنی Capacity Tier قرار می گیرند.
توصیه ها :
از آنجایی که FAST VP اداره داده ها در یک Pool را بر اساس الگوهای دسترسی به داده ها و کارایی ذخیره سازی انجام می دهد، بهتر است که تفاوت های بین مقادیر multiple tier را درک کنید. جدول زیر، تفاوت های اصلی بین Tier ها و درایوهای تشکیل دهنده ی آنها را نمایش می کند.

مشخصات
استوریج MSA 1040
همانطور که می دانیم ، امروزه در تمام سازمان ها دو قابلیت Entry consolidation و
*
ویژگی های برجسته استوریج MSA 1040 :
سادگی : ساده تر شدن تنظیمات و پیکربندی ، معماری انعطاف پذیر و ساده سازی مدیریت ویژگی های کلیدی این استوریج می باشد .
سرعت : استوریج MSA 1040 در مقایسه با P2000 G3 عملکردی بیشتر ارائه می هد ، در واقع این استوریج افزایش 50 درصدی عملکرد را به همراه دارد .
مقرون به صرفه : پیکربندی iSCSI / SAS / Fibre Channel در این استوریج منجر به کاهش هزینه ها می شود.
آینده نگر: معماری به کار رفته در این استوریج بسیار انعطاف پذیر است و به گونه ای است که قابلیت ارتقا به MSA 2040 را ارائه می دهد.
ویژگی های استوریج MSA 1040 :
| Features | |
| NUMBER OF CONTROLLER NODES | 2 |
|---|---|
| PROCESSORS/MEMORY PER ARRAY | 2/- |
| NUMBER OF DRIVES | 99 SFF 48 LFF |
| TOTAL CACHE | 6GB |
| MAX FAST CACH (FLASH CACH) | |
| ON-NODE CACHE | 6 GB |
| ARRAY ENCLOSURE(CHASSIS HEIGHT) | |
| 10 GBE ISCSI MAX TOTAL PORTS PER ARRAY | |
| 10GB/S FCOE HOST PORTS | |
| MAX RAW CAPACITY | 480 LFF 178.2 SFF |
| RAID LEVELS | 0,1,5,6,10,50 |
| NUMBER OF ADD-ON DRIVE ENCLOSURES | 3 |
منبع :
مشخصات
انواع سرور

![]()
شرکت
سرورها ، ذخیره ساز ها ، تجهیزات شبکه ، مشاوره و پشتیبانی (شامل : خدمات ، نرم افزار و خدمات اقتصادی)
تقسیم شدن شرکت HP به این منظور بود که شرکت هیولت پاکارد نام خود را به HP تغییر دهد و شرکت (Hewlett Packard Enterprise (HPE به عنوان یک شرکت تازه تاسیس از آن استخراج شود. کمپانی HP،که فعالیت های خود را در زمینه کامپیوترهای شخصی و چاپگرها ادامه داد و ادامه می دهد ، لوگو و نشانه قدیمی خود را حفظ کرد . در حالی که کمپانی تازه تاسیس شده تحت نماد تجاری جدید HPE فعالیت می کند. شایان ذکر است که درآمد HPE در سال 2015 اندکی کمتر از کمپانی قدیمی HP بود.
از جمله مهم ترین قدم هایی که کمپانی HPE در زمینه ذخیره ساز ها برداشت به اختیار گرفتن کمپانی 3PAR در سال 2010 بود .این کمپانی در زمینه تولید استوریج و محصولات مربوط به ذخیره سازی اطلاعات فعالیت گسترده ای داشت و جز برندهای مطرح بود.
انواع سرور HP
از جمله
- (Rack Servers (DL – سرور های رک مونت HP
- (Tower Servers (ML – سرور های ایستاده HP
- (Blade System (BL – سرور های تیغه ای HP
- Integrated Systems
- Apollo Servers
هر کدام از موارد فوق برحسب نیاز و تقاضایی که شبکه سازمان تقبل کند ، می توانند مفید واقع شوند . لازم به ذکر است که سرور های ML ، DL و BL از خانواده سرورهای Proliant کمپانی HPE می باشند.
سوالی که پیش می آید این است که با توجه به اینکه کمپانی های دیگری در زمینه تولید سرور فعالیت دارند ، کدام برند بیشتر مورد قبول سازمان های واقع در ایران می باشد؟
همانطور که می دانید امروزه سرورهای HPE در نسل های مختلف جزء لاینفکی از زیرساخت مراکز دولتی و خصوصی کشور عزیزمان ایران را تشکیل می دهند. این سرورها با توجه به سهولت استفاده از آنها ، کارایی بالا، قیمت پایین و خدمات پس از فروش متنوع در کشورمان از جایگاه ویژه ای برخوردار می باشند. همچنین باید این نکته را نیز در نظر داشت که این کمپانی در تولید سرورهای خود توانسته است با ایجاد تنوع در محصول نیازهای مربوطه را در رده های مختلف از شبکه های کوچک تا مراکز داده به شکل کاملی پوشش دهد.
متخصصین ما آمادهاند تا در صورت وم با حضور در سازمان ضمن تحلیل دقیق نیازهایتان و با در نظر گرفتن محدودیتهای مالی ، بهینهترین راهکار را در خصوص انتخاب سرور HP به شما معرفی نمایند . علاوه بر این می توانید از کارشناسان ما در خصوص
منبع :
مشخصات
A
In a standard server-rack configuration, one rack unit or 1U—19 inches (480 mm) wide and 1.75 inches (44 mm) tall—defines the minimum possible size of any equipment. The principal benefit and justification of blade computing relates to lifting this restriction so as to reduce size requirements. The most common computer rack form-factor is 42U high, which limits the number of discrete computer devices directly mountable in a rack to 42 components. Blades do not have this limitation. As of 2014, densities of up to 0 servers per blade system (or 1440 servers per rack) are achievable with blade systems.[2]
Blade enclosure
Enclosure (or chassis) performs many of the non-core computing services found in most computers. Non-blade systems typically use bulky, hot and space-inefficient components, and may duplicate these across many computers that may or may not perform at capacity. By locating these services in one place and sharing them among the blade computers, the overall utilization becomes higher. The specifics of which services are provided varies by vendor.

![]()
HP BladeSystem c7000 enclosure (populated with 16 blades), with two 3U UPS units below
Power
Computers operate over a range of DC voltages, but utilities deliver power as AC, and at higher voltages than required within computers. Converting this current requires one or more power supply units (or PSUs). To ensure that the failure of one power source does not affect the operation of the computer, even entry-level servers may have redundant power supplies, again adding to the bulk and heat output of the design.
The blade enclosure's power supply provides a single power source for all blades within the enclosure. This single power source may come as a power supply in the enclosure or as a dedicated separate PSU supplying DC to multiple enclosures.[3][4] This setup reduces the number of PSUs required to provide a resilient power supply.
The popularity of blade servers, and their own appetite for power, has led to an increase in the number of rack-mountable uninterruptible power supply (or UPS) units, including units targeted specifically towards blade servers (such as the BladeUPS).
Cooling
During operation, electrical and mechanical components produce heat, which a system must dissipate to ensure the proper functioning of its components. Most blade enclosures, like most computing systems, remove heat by using fans.
A servers. Newer blade-enclosures feature variable-speed fans and control logic, or even liquid cooling systems[5][6] that adjust to meet the system's cooling requirements.
At the same time, the increased density of blade-server configurations can still result in higher overall demands for cooling with racks populated at over 50% full. This is especially true with early-generation blades. In absolute terms, a fully populated rack of
Networking
Blade servers generally include integrated or optional network interface controllers for Ethernet or host adapters for Fibre Channel storage systems or converged network adapter to combine storage and data via one Fibre Channel over Ethernet interface. In many blades at least one interface is embedded on the motherboard and extra interfaces can be added using mezzanine cards.
A blade enclosure can provide individual external ports to which each network interface on a blade will connect. Alternatively, a blade enclosure can aggregate network interfaces into interconnect devices (such as switches) built into the blade enclosure or in networking blades.[8][9]
Storage
The ability to boot the blade from a storage area network (SAN) allows for an entirely disk-free blade, an example of which implementation is the Intel Modular Server System.
Other blades
Since blade enclosures provide a standard method for delivering basic services to computer devices, other types of devices can also utilize blade enclosures. Blades providing switching, routing, storage, SAN and fibre-channel access can slot into the enclosure to provide these services to all members of the enclosure.
Systems administrators can use storage blades where a requirement exists for additional local storage.[10][11][12]
Uses
![]()
![]()
Cray XC40 supercomputer cabinet with 48 blades, each containing 4 nodes with 2 CPUs each
Blade servers function well for specific purposes such as web hosting, virtualization, and cluster computing. Individual blades are typically hot-swappable. As users deal with larger and more diverse workloads, they add more processing power, memory and I/O bandwidth to blade servers. Although blade server technology in theory allows for open, cross-vendor system, most users buy modules, enclosures, racks and management tools from the same vendor.
Eventual standardization of the technology might result in more choices for consumers;[13][14] as of 2009 increasing numbers of third-party software vendors have started to enter this growing field.[15]
Blade servers do not, however, provide the answer to every computing problem. One can view them as a form of productized server-farm that borrows from mainframe packaging, cooling, and power-supply technology. Very large computing tasks may still require server farms of blade servers, and because of blade servers' high power density, can suffer even more acutely from the heating, ventilation, and air conditioning problems that affect large conventional server farms.
History
Developers first placed complete microcomputers on cards and packaged them in standard 19-inch racks in the 1970s, soon after the introduction of 8-bit microprocessors. This architecture was used in the industrial process controlindustry as an alternative to minicomputer-based control systems. Early models stored programs in EPROM and were limited to a single function with a small real-time executive.
The VMEbus architecture (ca. 1981) defined a computer interface which included implementation of a board-level computer installed in a chassis backplane with multiple slots for pluggable boards to provide I/O, memory, or additional computing.
In the 1990s, the PCI Industrial Computer Manufacturers Group PICMG developed a chassis/blade structure for the then emerging Peripheral Component Interconnect bus PCI which is called CompactPCI. Common among these chassis-based computers was the fact that the entire chassis was a single system. While a chassis might include multiple computing elements to provide the desired level of performance and redundancy, there was always one master board in charge, coordinating the operation of the entire system.
PICMG expanded the CompactPCI specification with the use of standard Ethernet connectivity between boards across the backplane. The PICMG 2.16 CompactPCI Packet Switching Backplane specification was adopted in Sept 2001.[16] This provided the first open architecture for a multi-server chassis. PICMG followed with the larger and more feature-rich AdvancedTCA specification, targeting the telecom industry's need for a high availability and dense computing platform with extended product life (10 years). While AdvancedTCA system and boards typically sell for higher prices than blade servers, AdvancedTCA promote them for telecommunications customers.
The first commercialized blade server architecture[citation needed] was invented by Christopher Hipp and David Kirkeby, and their patent (US 6411506) was assigned to Houston-based RLX Technologies.[17] RLX, which consisted primarily of former Compaq Computer Corporation employees, including Hipp and Kirkeby, shipped its first commercial blade server in 2001.[] RLX was acquired by Hewlett Packard in 2005.[19]
The name blade server appeared when a card included the processor, memory, I/O and non-volatile program storage (flash memory or small hard disk(s)). This allowed manufacturers to package a complete server, with its operating system and applications, on a single card / board / blade. These blades could then operate independently within a common chassis, doing the work of multiple separate server boxes more efficiently. In addition to the most obvious benefit of this packaging (less space consumption), additional efficiency benefits have become clear in power, cooling, management, and networking due to the pooling or sharing of common infrastructure to support the entire chassis, rather than providing each of these on a per server box basis.
In 2011, research firm IDC identified the major players in the blade market as HP, IBM, Cisco, and Dell.[20] Other companies selling blade servers include AVADirect, Oracle, Egenera, Supermicro, Hitachi, Fujitsu, Rackable (hybrid blade), Cirrascale and Intel Corporation.
Blade models[edit]

![]()
Cisco UCS blade servers in a chassis
Though independent professional computer manufacturers such as Supermicro offer blade servers, the market is dominated by large public companies such as Cisco Systems, which had 40% share by revenue in Americas in the first quarter of 2014.[21] The remaining prominent brands in the blade server market are HPE, Dell and IBM, though the latter sold its x86 business to Lenovo in 2014.[22]
In 2009, Cisco announced blades in its Unified Computing System product line, consisting of 6U high chassis, up to 8 blade servers in each chassis. It has a heavily modified Nexus 5K switch, rebranded as a fabric interconnect, and management software for the whole system.[23] HP's line consists of two chassis models, the c3000 which holds up to 8 half-height ProLiant line blades (also available in tower form), and the c7000 (10U) which holds up to 16 half-height ProLiant blades. Dell's product, the M1000e is a 10U modular enclosure and holds up to 16 half-height PowerEdge blade servers or 32 quarter-height blades.
منبع :
مشخصات
Horizon، پلتفرمی برای مجازی سازی دسکتاپ
VMware محصولات گوناگونی از Horizon را عرضه کرده است که همه این محصولات برای ارائه خدمات به کاربران در یک مجموعه واحد به نام VMware Horizon Suite قرار می گیرند. ادمین با استفاده از مجموعه Horizon می تواند دسکتاپ ها، اپلیکیشن ها و داده را در سراسر انواع endpoint ها توزیع کند و پاسخگوی تقاضای کاربران برای دسترسی به فایل ها و داده ها در انواع دستگاه ها و در محیط خانه، اداره و … باشد. این مجموعه شامل راهکارهای Horizon View، Horizon Mirage و Horizon Workspace می شود و از قابلیت های زیر پشتیبانی می کند:
- اپلیکیشن ها و دسکتاپ های مجازی
- مدیریت لایه بندی شده ی windows image به همراه مدیریت متمرکز، بازیابی و پشتیبان گیری
- به اشتراک گذاری فایل
- مدیریت فضای کاری متغیر
- Application catalog and management
- مدیریت متمرکز مبتنی بر policy

VMware Horizon View
Horizon View یک راهکارِ مجازی سازی دسکتاپ برای تسهیل مدیریت IT، افزایش امنیت و کنترل دسترسی بر کاربرنهایی است که هزینه ها را نیز کاهش می دهد. با استفاده از Horizon View، مدیر شبکه می تواند مدیریت هزاران دسکتاپ را اتوماتیک و ساده سازی کند و از طریق واحد مرکزی با اطمینان دسکتاپ را به عنوان یک سرویس به کاربران تحویل دهد.
مهمترین بخش در Horizon view واسط اتصال یا همان View Manager است که کاربران را به دسکتاپ های مجازی موجودشان در دیتاسنتر متصل می کند. همچنین View شامل پروتکل نمایش از راه دور PCoIP است که جهت ارائه بهترین تجربه کاربری ممکن ، تحت ارتباطات LAN یا WAN استفاده می شود. در نتیجه به کاربر یک دسکتاپ شخصی قدرتمند برای دسترسی به داده، اپلیکیشن ها، ارتباطات یکپارچه (صوت، تصویر و ) و گرافیک 3D تعلق می گیرد.
علاوه بر موارد ذکر شده، Horizon View شامل ThinApp برای مجازی سازی اپلیکیشن و Composer (برای اینکه به سرعت image های دسکتاپ را از طریق یک golden image ایجاد کند) می شود. کاربران از طریق چندین روش می توانند به دسکتاپ های مجازی خود متصل شوند که شامل View software client بر روی لپتاپ، View iPad یا Android client، مرورگر وب یا یک دستگاه thin-client می شود.

برخی از مولفه های اصلی در Horizon View عبارتند از:
- View Connection Server – یک سرویس نرم افزاری است که از طریق احراز هویت و سپس هدایت درخواست های ورودی کاربر به دسکتاپ مجازی، دسکتاپ فیزیکی یا سرور ترمینال مناسب به عنوان واسطی برای اتصال کلاینت عمل می کند.
- View Agent – سرویسینرم افزاری است که بر روی همه ماشین های مجازی مهمان، سیستم های فیزیکی یا سرورهای ترمینال نصب می شود تا بتوانند توسط View مدیریت شوند.
- View Client – اپلیکیشنی نرم افزاری است که با View Connection Server ارتباط برقرار می کند تا به کاربران اجازه اتصال به دسکتاپ ها را بدهد.
- View Client with Local Mode – نسخه ای از View Client است که جهت پشتیبانی از ویژگی local desktop ارائه شده است و به کاربران اجازه دانلود ماشین های مجازی و استفاده از آنها بر روی سیستم های محلی خود را می دهد.
- View Administrator – یک اپلیکیشن وب است که اجازه کانفیگ View Connection Server ، استقرار و مدیریت دسکتاپ ها، کنترل احراز هویت کاربر، راه اندازی و ارزیابی رویدادهای سیستم و اجرای فعالیت های تحلیلی را می دهد.
- vCenter Server – سروری است که به عنوان administrator مرکزی برای هاست های ESX/ESXi عمل می کند. vCenter Server بخشی مرکزی را برای کانفیگ، اصلاح و مدیریت ماشین های مجازی موجود در دیتاسنتر فراهم می کند.
- View Composer – سرویسی نرم افزاری است که بر روی vCenter server نصب می شود تا View بتواند به سرعت چندین دسکتاپ linked-clone را از یک Base Image واحد در شبکه مستقر نماید.
- View Transfer Server – یک سرویس نرم افزاری است که انتقال داده میان دیتاسنتر و دسکتاپ های View را مدیریت و تسهیل می کند. برای پشتیبانی از دسکتاپ هایی که View Client with Local Mode را اجرا می کنند، View Transfer Server مورد نیاز است.
VMware Horizon Mirage
کمپانی VMware راهکار Mirage را در سال 2012 از شرکت Wanova خریداری نمود و در مجموعه VMware Horizon Suite قرار داد. Mirage راهکاری منحصر به فرد برای مدیریت متمرکز دسکتاپ های فیزیکی یا مجازی، لپ تاپها و یا دستگاه های شخصی مورد استفاده در محیط کار است. هنگامی که Mirage بر روی یک windows PC نصب شده باشد، کپی کاملی را از آن Windows بر روی دیتاسنتر قرار می دهد و آنها را با یکدیگر همگام نگاه میدارد. این همگام سازی شامل تغییراتی از جانب کاربر نهایی در windows می شود که بر روی دیتاسنتر بارگذاری می شوند. همچنین شامل تغییراتی از جانب مدیر شبکه در رابطه با IT است که دانلود شده و به طور مستقیم بر روی windows PC کاربر اعمال می شود. Mirage توانایی مدیریت مرکزی image های دسکتاپ ها را دارد در حالی که مجوز مدیریت محیط local کاربر را به خود کاربرنهایی نیز می دهد.

Mirage می تواند PC را به لایه هایی مجزا تقسیم کند که به طور مستقل مدیریت می شوند: لایه Base Image، یک لایه شامل اپلیکیشن هایی نصب شده توسط کاربر و اطلاعات ماشین همچون machine ID و یک لایه شامل داده و فایل های شخصی کاربر.
در این روش، مدیر IT می تواند یک read-only Base Image ایجاد کند که معمولا شامل سیستم عامل (OS) و اپلیکیشن های اصلی همچون Microsoft Office و راهکارهای آنتی ویروسی می شود که به صورت مرکزی مدیریت می شوند. این Base Image می تواند بر روی کپی ذخیره شده از هر PC مستقر شود و سپس با نقطه نهایی هماهنگ شود. به دلیل لایه بندی، Image می تواند patch، بروزرسانی و re-synchronized شود، بدون اینکه اپلیکیشن های نصب شده توسط کاربر یا داده را بازنویسی کند. این ویژگی منجر به بهینه سازی در عملیات شبکه خواهند شد و موارد استفاده زیر را خواهد داشت:
- مدیریت Image واحد – ادمین می تواند یک Image اصلی را مدیریت کند و آن را با هزاران نقطه نهایی
(endpiont) همگام سازد. - مهاجرت سخت افزاری – با جایگزین کردن Base Image مرتبط با PC یک کاربر نهایی، دسکتاپ کاربر از جمله اپلیکیشن ها، داده و تنظیمات شخصی می تواند به سخت افزار جدید از جمله سخت افزاری از سازنده ای دیگر منتقل شود. این فرآیند را می توان به عنوان بخشی از یک فرآیند مهاجرت سخت افزاری یا برای جایگزینی یک PC دچار خرابی، یا یده شده استفاده نمود.
- اصلاح ریموت اپلیکیشن های آسیب دیده – با اجرای یک Base image ، ادمین می تواند با ریموت زدن به کپی اصلی موجود در دیتاسنتر، مشکلات اپلیکیشن های اصلی یا OS را اصلاح کند.
- مهاجرت محلی از ویندوز Win xP به Win 7 – با جایگزین کردن Base Image مرتبط با PC یک کاربر نهایی، دسکتاپ کاربر از جمله داده و تنظیمات شخصی می تواند تحت شبکه و بدون زیرساخت اضافی از Win XP به Win 7 منتقل شود
برخی از مولفه های موجود در VMware Mirage عبارتند از:
- Mirage Client – فایلی قابل اجرا بر روی client endpoint است و به یک Mirage server یا به load balanced Mirage servers برای واکشی بروزرسانی ها از دسکتاپ مجازی مرکزی، متصل می شود.
- Mirage Management Server – یک کنسول اجرایی است که Mirage Server Cluster را کنترل و مدیریت می کند
- Mirage Server – در دیتاسنتر قرار می گیرد و عملکرد اصلی آن همگام سازی کلاینت ها با دسکتاپ مجازی مرکزی است. همچنین در برابر تحویل لایه Base ، لایه اپلیکیشن و دسکتاپ مجازی مرکزی به کلاینت ها مسئول است و آنها را بر روی کلاینت یکپارچه می کند.
- Mirage Management Console – یک GUI است که برای نگهداری، مدیریت و نظارت بر endpoint های نصب شده استفاده می شود. ادمین می تواند Mirage client ها، لایه های Base و لایه های اپلیکیشن را کانفیگ کند. همچنین با استفاده از Management console می تواند بر روی دسکتاپ مجازی مرکزی تغییرات را اعمال نماید.
- Centralized Virtual Desktop – محتوای کامل هر PC است. این داده به Mirage Server منتقل می شود و در آنجا ذخیره می گردد. از دسکتاپ مجازی مرکزی برای مدیریت، بروزرسانی، patch، پشتیبان گیری، عیب یابی، بازیابی و ارزیابی دسکتاپ در دیتاسنتر استفاده می شود.
VMware Horizon Workspace
یک نرم افزار مدیریت اینترپرایز است که واسط مرکزی واحدی را جهت دسترسی ایمن فراهم می کند. شما در هر زمان و از هر مکانی می توانید از طریق لپتاپ خود، کامپیوترهای خانگی و دستگاه های موبایل android یا ios به اپلیکیشن ها، دسکتاپ ها، فایل ها و سرویسهای وب کمپانی دسترسی یابید
مدیران شبکه از طریق پلتفرم مدیریت مبتنی بر وب می توانند مجموعه ای customize از دسترسی به اپلیکیشن و داده را برای کاربران فراهم کنند که شامل تنظیمات security policy و مجوز استفاده از اپلیکیشن ها می شود. سازمان ها می توانند به سادگی دستگاه های جدید، کاربران جدید یا اپلیکیشن های جدید را برای یک گروه از کاربران بدون نیاز به کانفیگ دوباره دستگاه ها یا endpoint ها اضافه کنند.

برخی از مولفه های اصلی در Horizon Workspace عبارتند از:
- Workspace Configurator – یک کنسول مدیریتی و واسط کاربری تحت web است که برای مدیریت مرکزی SSL همچنین تنظیمات شبکه، Gateway، vCenter و SMTP در Horizon vApp استفاده می شود.
- Workspace Manager – یک واسط اجرایی تحت وب است که کانفیگ application catalog، user entitlement management و system reporting را ممکن می سازد.
- Workspace Data – به عنوان یک datastore برای فایل های کاربر عمل می کند. ت های به اشتراک گذاری فایل ها را کنترل و سرویس های نمایش فایل را فراهم می کند.
- Workspace Connector – قابلیت هایی را برای احراز هویت کاربر local و پیوست Active Directory و سرویس های همگام سازی فراهم می کند. ThinApp catalog loading و View pool synchronization از دیگر خدماتی است که ارائه می دهد.
- Workspace Gateway – به عنوان یک namespace واحد برای همه تعاملات Workspace عمل می کند و دامنه ای برای دسترسی به Worspace ایجاد می کند. همچنین به عنوان بخشی مرکزی برای تجمیع همه اتصالات کلاینت است و ترافیک کلاینت را به مقصد درست مسیریابی می کند.
مشخصات
Hyper-V Architecture
Hyper-V features a Type 1 hypervisor-based architecture. The hypervisor virtualizes processors and memory and provides mechanisms for the virtualization stack in the root partition to manage child partitions (virtual machines) and expose services such as I/O devices to the virtual machines.
The root partition owns and has direct access to the physical I/O devices. The virtualization stack in the root partition provides a memory manager for virtual machines, management APIs, and virtualized I/O devices. It also implements emulated devices such as the integrated device electronics (IDE) disk controller and PS/2 input device port, and it supports Hyper-V-specific synthetic devices for increased performance and reduced overhead.
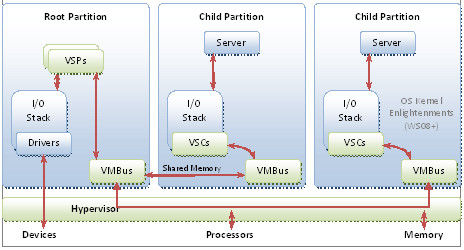
The Hyper-V-specific I/O architecture consists of virtualization service providers (VSPs) in the root partition and virtualization service clients (VSCs) in the child partition. Each service is exposed as a device over VMBus, which acts as an I/O bus and enables high-performance communication between virtual machines that use mechanisms such as shared memory. The guest operating system’s Plug and Play manager enumerates these devices, including VMBus, and loads the appropriate device drivers (virtual service clients). Services other than I/O are also exposed through this architecture.
Starting with Windows Server 2008, the operating system features enlightenments to optimize its behavior when it is running in virtual machines. The benefits include reducing the cost of memory virtualization, improving multicore scalability, and decreasing the background CPU usage of the guest operating system.
The following sections suggest best practices that yield increased performance on servers running Hyper-V role.
source: microsoft.com
مشخصات
نرم افزار EMC FAST به محصولات EMC Unity اجازه می دهد تا از درایوهای Flash با کارایی بالا استفاده کنند. نرم افزار FAST شامل Fully Automated Storage Tiering برای (Virtual Pools (FAST VP و FAST Cache است. این دو ویژگی در کنار هم کار می کنند تا از فضای ذخیره سازی درون سیستم به صورت مؤثر استفاده شود. هر یک از این ویژگی های نرم افزاری تضمین می کند که فعال ترین داده ها از طریق Flash پشتیبانی می شوند.
هنگامی که ویژگیِ FAST VP فعال شود، این ویژگی آمارهایِ Performance روی هر [1] slice در یک Pool را اندازه گیری و ثبت می کند. در ادامه، FAST VP این داده ها را تجزیه و تحلیل می کند و تصمیم می گیرد تا داده ها را به tier های مختلف انتقال دهد (با توجه به میزان استفاده از داده) تا Performance یک Pool را بیشینه کند و از فضای درون Pool به طور موثری بهرمند شود. Slice هایی که بیشترین استفاده را دارند به طور خودکار به Tier های بالاتر در یک Pool منتقل می شوند، در حالی که Slice هایی که استفاده کمتری دارند به Tier های پایین تر منتقل می شوند. داده هایی که از قبل روی Flash در یک Pool قرار گرفته اند از فضای Fast Cache استفاده نمی کنند که این قابلیت اجازه می دهد تا داده های مستقرِ بیشتری بر روی هارد دیسک ها از مزایای فلش Fast VP بهره مند شوند.
این مقاله برای مشتریان ، شرکا و کارکنان فاراد در نظر گرفته شده است که از ویژگی های FAST VP و FAST CACHE در خانواده EMC Unity از سیستم های استوریج استفاده می کنند. استفاده از این ویژگی با EMC Unity و نرم افزار مدیریت EMC همراه می شود.
بطور معمول وقتی داده ای ایجاد می شود ابتدا در بالاترین tier قرار می گیرد و با توجه به میزان نوشتن و خواندن از آن داده ، استوریج نسبت به انتقال داده در tier مناسب اقدام می کند. از این روند نیز به عنوان چرخه حیات داده ها یاد شده است. EMC Unity سیستم ذخیره سازی کاملا اتوماتیک (Fully Automated Storage Tiering) را برای Pool های مجازی (FAST VP) ارائه می دهد که بر الگوهای دسترسی به داده (خواندن و نوشتن داده ها) درونِ Pool های سیستم نظارت می کند و به صورت پویا خود را تطبیق می دهد از طریقِ در نظر گرفتن و انتخاب مناسب ترین tier که میزان کارایی (Performance) مورد نیاز را ارائه می دهد. FAST VP درایوها را به سه دسته تقسیم می کند. این سطوح عبارتند از:
- Extreme Performance Tier – شامل درایوهای Flash است
- Performance Tier – شامل درایوهای (Serial Attached SCSI (SAS است
- Capacity Tier – شامل درایوهای (Near-Line SAS (NL-SAS

FAST VP به کاهش هزینه (Total Cost of Ownership-TCO) با حفظ Performance و با استفاده از ساختار Pool می پردازد. به جای ایجاد یک Pool با یک نوع درایو، مخلوط کردن Flash، SAS و NL SAS درایوها می توانند از طریق کاهش تعداد درایوها و استفاده از درایوهایی با ظرفیت بیشتر به کاهش هزینه های یک پیکربندی کمک کنند. داده هایی که دارای سطح عملکرد بالایی هستند در درایو های Flash قرار می گیرند، در حالی که داده هایی که فعالیت کمتری دارند در SAS یا NL-SAS قرار می گیرند.
EMC Unity یک رویکرد واحد برای ایجاد منابع ذخیره سازی در سیستم دارد. Block LUNs، File Systems و VMware Datastores همه می توانند در یک Pool واحد وجود داشته باشند و همگی می توانند از ویژگی های FAST VP بهره مند شوند. در تنظیمات سیستم با حداقل مقدار Fast VP ، Flash به راحتی از درایوهای Flash برای داده های فعال با عملکرد بالا , صرف نظر از نوع منبع استفاده می کند. میزان عملکرد برای تمام داده ها در یک Pool در مقایسه با یکدیگر بررسی می شوند و بیشترین اطلاعات مورد استفاده ، در درایو های با کارایی بالا (درایو های Flash) قرار می گیرند. ت های Tiering در مقاله های بعد توضیح داده خواهد است.
لایسنس FAST VP :
در Fast VP ، Unity روی سیستم های Unity Hybrid و UnityVSA پشتیبانی می شود. برای سیستم های Unity Hybrid ، FAST VP از طریق بسته ی نرم افزاری EMC Unity Essentials که شامل تمامی سیستم های Unity Hybrid می باشد فعال می شود. FAST VP برای UnityVSA با License نرم افزار پایه فعال می شود. هنگامی که این License ها نصب می شوند، ویژگی های مرتبط FAST VP در دسترس هستند:
- توانایی ایجاد Pool با انواع چندین درایو
- توانایی تنظیم ت های Tiering روی Block LUN ها، File Systems و VMware Datastores.
- توانایی دسترسی به تب FAST VP در Pool properties window یا storage resource properties window

[1] Slice : سیستم LUN های شما را به تکه های کوچک (Slice) تقسیم می کند و به این Slice ها یک درجه حرارتی ( با توجه به کارایی ) اختصاص داده می شود. مثلا اگر Slice هایی که به طور مداوم در دسترس باشد را Hot Slice و Slice هایی که به ندرت از آن ها استفاده می شود را Cold Slice گویند و این Slice ها دارای حجم 256MB می باشند.
منبع : فاراد سیستم
مشخصات
در یک شبکه lan، اگر تمامی بسته ها به مقصد سگمنت های دیگر شبکه توسط روتری یکسان فرستاده شوند، هنگامی که gateway از کار بیافتد، همه ی هاست هایی که از آن روتر به عنوان next-hop پیش فرض استفاده می کنند در برقراری ارتباط با شبکه های خارجی موفق نخواهند بود. برای رفع این مشکل، سیسکو پروتکل اختصاصی HSRP را ارائه داده است که برای gateway ها در یک lan ، افزونگی ایجاد می کند تا قابلیت اطمینان شبکه را افزایش دهد.
پروتکل HSRP چیست ؟
یکی از راه های دستیابی به uptime نزدیک به 100 درصد در شبکه، استفاده از
با به اشتراک گذاشتن یک آدرس IP و آدرس MAC (لایه 2) میان دو یا تعدادی بیشتری از روترها، آنها می توانند به عنوان یک روتر مجازیِ واحد (virtual router) عمل نمایند. روترهای عضو در این گروه، به طور مستمر برای رصد وضعیت روترهای دیگر پیام هایی را با یکدیگر مبادله می نمایند. در نتیجه هر روتر مسئولیت مسیریابی روتری دیگر را نیز بر عهده خواهد گرفت. و بر پایه این پروتکل، هاست ها می توانند بسته های IP را به آدرس MAC و IP پایداری ارسال نمایند.

مکانیزم های پویا برای تشخیص روتر
در ادامه مکانیزم های موجود برای تشخیص روتر توسط هاست تشریح می شود. بسیاری از این مکانیزم ها منجر به تاب آوری (resiliency) بیشترِ شبکه نمی شوند. این مسئله به این معنا می تواند باشد که در ابتدا برای پروتکل ها قابلیت تاب آوریِ شبکه در نظر گرفته نمی شد یا اینکه اجرای پروتکل برای هر هاست از شبکه ممکن نبود. باید این را در نظر داشته باشید که بسیاری از هاست ها، تنها مجوز تنظیمِ default gateway را به شما می دهند.
Proxy Address Resolution Protocol
برخی از هاست ها از پروتکل (proxy Address Resolution Protocol (ARP برای انتخاب یک روتر استفاده می کنند. هنگامی که یک هاست proxy ARP را اجرا می کند، به منظور دستیابی به آدرس IP هاستی که قصد ارتباط با آن را دارد، یک درخواست ARP ارسال می کند. فرض کنید روتر A در شبکه، از طرف هاستِ مقصد پاسخ می دهد و آدرس MAC اش را در اختیار می گذارد. به واسطه ی پروتکل ARP ، هاست مبدا با هاست راه دور به گونه ای برخورد می کند که گویی به همان سگمنت از شبکه متصل است. اگر روتر A از کار بیافتد، هاست مبدا به ارسال بسته ها به هاست مقصد از طریق آدرس MAC مربوط به روتر A ادامه می دهد، با آنکه این بسته ها به مقصدی ارسال نمی شوند و از بین می روند. شما می توانید منتظر بمانید تا پروتکل ARP ، آدرس MAC یک روتر دیگر بر روی همان سگمنت ،به فرض روتر B ، را به دست آورد. آدرس روتر B از طریق ارسال یک درخواستِ دیگر ARP یا راه اندازی مجددِ هاست مبدا برای ارسال درخواست ARP به دست می آید. از طرف دیگر برای مدت زمانی قابل توجه، هاست مبدا نمی تواند با هاست راه دور ارتباط برقرار کند، با وجود اینکه انتقال بسته هایی که پیش از این توسط روتر A ارسال می شدند از طریق روتر B میسر می شود.
Dynamic Routing Protocol
برخی از هاست ها یک پروتکل مسیریابی پویا همچون (Routing Information Protocol (RIP یا (Open Shortest Path First (OSPF را اجرا می کنند تا روترها را بیابند. نقطه ضعفِ پروتکل RIP، سرعتِ کُندِ آن برای به کارگیری تغییرات در توپولوژی است. اجرای یک پروتکل مسیریابی پویا بر روی هر هاست، به دلایلی ممکن است، عملی نباشد. که این دلایل شاملِ administrative overhead ، processing overhead ، مسائل امنیت یا عدم امکانِ پیاده سازی پروتکل بر روی برخی از پلتفرم ها می شود.
(ICMP Router Discovery Protocol (IRDP
به هنگام عدم دسترسی پذیری به یک مسیر، برخی از هاست های جدیدتر از IRDP برای یافتن روتری جدید استفاده می کنند. هاستی که IRDP را اجرا می کند به پیام های multicast دریافت شده از روتر پیش فرضِ خود گوش فرا می دهد و هنگامی که پس از مدتی پیام های hello را دریافت نکند، از یک روتر جایگزین بهره می برد.
Dynamic Host Configuration Protocol
پروتکل DHCP مکانیزمی را برای انتقال اطلاعات کانفیگ به هاست ها بر روی شبکه TCP/IP ارائه می دهد. این اطلاعات کانفیگ معمولا شامل آدرس IP و default gateway می شود. اگر default gateway از کار بیافتد، هیچ مکانیزمی برای تغییر به روتری جایگزین وجود ندارد.
عملیات HSRP
در بسیاری از هاست ها تشخیص پویا پشتیبانی نمی شود. بنا به دلایلی که پیشتر ذکر شد، اجرای یک مکانیزم تشخیص پویای روتر بر روی هر هاست از شبکه نیز ممکن است تحقق پذیر نباشد. در نتیجه پروتکل HSRP برای این هاست ها failover service را فراهم می کند.
با استفاده از HSRP ، مجموعه ای از روترها به صورت همزمان فعالیت می کنند تا به عنوان یک روتر مجازی واحد به هاست های موجود بر روی LAN نشان داده می شوند. این مجموعه به عنوان گروه HSRP یا گروه standby شناخته می شوند. یک روترِ برگزیده از این گروه مسئولیت ارسال بسته هایی را بر عهده دارد که هاست ها به روتر مجازی می فرستند. این روتر به عنوان Active router شناخته می شود و روتر دیگر به عنوان Standby router انتخاب می شود. هنگامی که روتر Active از کار بیافتد، روتر standby وظایفِ ارسال بسته را بر عهده می گیرد. با وجود آنکه تعداد دلخواهی از روترها پروتکل HSRP را می توانند اجرا نمایند، تنها روتر Active ، بسته هایی را ارسال می کند که به روتر مجازی فرستاده شده اند.
برای به حداقل رساندن ترافیک شبکه، به محض اینکه پروتکل فرآیند انتخاب را کامل کرد، تنها روترهای Active و standby پیام های HSRP را به صورت دوره ای می فرستند. اگر روتر Active از کار بیافتد، روتر standby به عنوان روتر Active فعال خواهد شد. اگر یک روتر standby از کار بیافتد یا به یک روتر Active تبدیل شود، سپس روتر دیگری به عنوان روتر standby انتخاب می شود.
بر روی یک LAN مشخص، چندین گروه standby همزمان می توانند حضور و یا همپوشانی داشته باشند. هر گروه standby یک روتر مجازی را شبیه سازی می کنند. روتری مشخص ممکن است در چندین گروه شرکت داشته باشد. در چنین مواقعی، روتر تایمر و وضعیت هر گروه را به صورت جداگانه نگهداری می کند.
هر گروه standby یک آدرس MAC و یک آدرس IP دارد.
ارتباطات در HSRP
با استفاده از پروتکل HSRP سه نوع از پیام های multicast میان دستگاه ها رد و بدل می شود:
Hello – پیام hello میان دستگاه های Active و Standby ارسال می شود (به صورت پیش فرض هر 3 ثانیه). اگر دستگاه Standby به مدت 10 ثانیه از سمت Active پیامی دریافت نکند، خودش نقش Active را بر عهده خواهد گرفت.
Resign – پیام resign از طرف روترِ active فرستاده می شود، هنگامی که این روتر قرار است آفلاین شود یا به دلایلی از نقش Active صرف نظر کند. این پیام به روتر Standby می گوید که برای نقش Active آماده شود.
Coup – پیام coup هنگامی استفاده می شود که روتر Standby می خواهد به عنوان روتر Active فعال شود (preemption).
وضعیت روترها در HSRP
روترها در پروتکل HSRP در یکی از وضعیت های زیر قرار می گیرند:
Active – حالتی است که ترافیک در حال ارسال است.
Init یا Disabled – حالتی است که روتر آماده نیست یا قادر به شرکت در فرآیند HSRP نیست.
Learn – حالتی است که هنوز آدرس IP مجازی تعیین نشده است و پیام hello از طرف روتر Active دیده نشده است.
Listen – حالتی است که یک روتر پیام های hello را دریافت می کند.
Speak – حالتی است که روتر پیام های hello را می فرستد و دریافت می کند.
Standby – حالتی است که روتر آماده می شود تا وظایف ارسال ترافیکِ مربوط به روتر Active را بر عهده بگیرد.
ویژگی های HSRP
Preemption
ویژگیِ Preemption در HSRP بلافاصله روتری با حداکثر اولویت را به عنوان روتر Active فعال می سازد. اولویت روتر در ابتدا از طریق مقدار priority تعیین می شود که توسط شما تنظیم شده است و سپس به واسطه آدرس IP . هرچه این مقدار بیشتر باشد، اولویت بالاتر است.
وقتی که یک روتر با اولویت بیشتر حق تقدم می یابد، یک پیام coup می فرستد. هنگامی که یک روتر Active با اولویتی کمتر پیامِ coup یا پیامِ hello را از یک روتر با اولویتی بالاتر دریافت کند، به وضعیت speak تغییر می کند و یک پیامِ resign می فرستد.
Preempt Delay
این ویژگی منجر خواهد شد که فرآیند preemption برای مدت زمانی قابل تنظیم به تعویق بیافتد، و در نتیجه روترِ با اولویت بالا اجازه خواهد یافت که پیش از دریافت نقشِ Active، جدول routing خود را پُر نماید.
Interface Tracking
این ویژگی به شما اجازه خواهد داد که اینترفیسی را بر روی روتر، برای نظارت بر فرآیند HSRP تعیین نمایید تا اولویت HSRP را برای گروهی معین تغییر دهد.
اگر line protocol مربوط به اینترفیس مشخص شده down شود، اولویت HSRP مربوط به این روتر کاهش یافته است. در نتیجه به روتر دیگری با اولویت بالاتر اجازه داده می شود تا Active شود. برای اینکه از Interafece Tracking در HSRP استفاده نمایید دستور زیر را به کار برید:
[Standby [group] track interface [priority
Multiple HSRP Group
ویژگی MHSRP به نسخه 10.3 از Cisco IOS اضافه شد. این ویژگی به اشتراک گذاری load و افزونگی در شبکه را در اختیار می گذارد. و اجازه خواهد داد که روترهای افزونه به طور کامل مورد بهره برداری قرار گیرند. در حالی که روتری در نقش Active ترافیکِ یک گروهِ HSRP را ارسال می کند، در همان حال در گروهی دیگر می تواند در وضعیت standby یا listen قرار بگیرد.
آدرس MAC و IP مجازی
آدرس IP مجازی توسط ادمین شبکه کانفیگ می شود. هاست آدرسِ IP مربوط به default gateway خود را برابر با این آدرس IP مجازی خواهد گذاشت و در این حالت روترِ Active به آن پاسخ خواهد داد. آدرس MAC مجازی بر طبق الگوی زیر ایجاد می شود:
##.0000.0C07.AC
بخشِ 0000.0C مربوط به شناسه OUI شرکت Cisco است. بخشِ 07.AC ،شناسه ی اعمال شده برای پروتکلِ HSRP است و ## شناسه ی گروه HSRP است که توسط ادمین شبکه کانفیگ می شود.
**************
برای پروتکل HSRP دو نسخه ارائه شده است که با توجه به نوع سوئیچ لایه 3 یا روتری که در اختیار دارید، می توانید یکی از این دو نسخه را استفاده نمایید. در زیر جدول تفاوت این دو نسخه آورده شده است.
| HSRPV1 | HSRPV2 | |
|---|---|---|
| Group Numbers | 0-255 | 0-4095 |
| Virtual MAC address | 0000.0c07.acXX (XX = group number) | 0000.0c9f.f (XXX = group number) |
| Multicast Address | 224.0.0.2 | 224.0.0.102 |
برای تنظیمِ پروتکل HSRP بر روی سوئیچ سیسکو لایه 3 و روتر سیسکو می توانید از این لینک کمک بگیرید.
مشخصات
نوآوری جوهر حیات هر کسب و کاری است. در صنعت ذخیره سازی، سرعت پیشرفت نوآوری هیچ گاه بالا نبوده است. ده سال پیش، پیشروی از هارد دیسک هایی با سرعت 10K به 15K RPM نوآورانه به حساب می آمد. اما اکنون همه چیز تغییر کرده است.
ظهور NVMe و بررسی آن
در این عصر مبتنی بر اطلاعات، میزان داده هایی که باید مدیریت شوند نسبت به آنچه که در چند سال گذشته سازمان های enterprise با آنها سر و کار داشتند، به طور چشم گیری افزایش یافته است. دغدغه های موجود پیرامون قابلیت پیش بینی پذیریِ کارایی، بسیاری از شرکت های enterprise را به سمت NVMe ها ترغیب کرده است. پروتکلِ ذخیره سازی ای که جایگزینی برای SCSI است و اکثر تکنولوژی های حافظهی نوظهور همچون تکنولوژی SCM از آن پشتیبانی می کنند.
از جمله مسائل موجود در سازمان ها، عبارتند از:
- نیاز به سرعت بیشتر – یک مثال در این زمینه، بارهای کاریِ تحلیلی است که در هوش مصنوعی و machine learning را بکار می روند. این بارهای کاری برای تصمیم گیری حساس به زمان هستند و تحمل تاخیر را ندارند. مثال های دیگر شامل بارهای کاری تراکنش در دیتابیس ها و OLTP می شود.
- نتایج غیرقابل پیشبینی که ناشی از تاخیر بی ثبات هستند – اغلب یکی از نگرانی ها قابلیت پیشبینی پذیری برای کارایی است. مشتریان علاوه بر اینکه نیاز به شروعی سریع با تاخیری کم در محیط خود دارند، همچنین به حفظ این سرعت نیاز خواهند داشت.
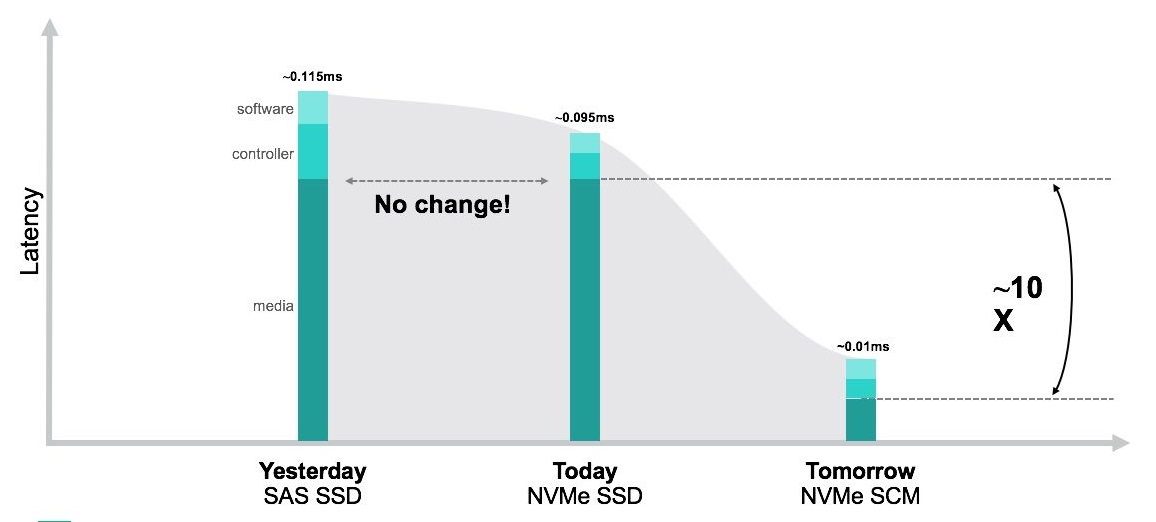
مقایسه NVMe SCM و نسل های پیشین
برای آشنایی بیشتر به ادامه مقاله مراجعه نمایید.
مشخصات
- تولید و فروش گچ پلیمری
- webdes
- داروخانه پلاس | داروخانه آنلاین شبانه روزی
- ترشیز وب
- بانک اطلاعات مشاغل
- لباس زیر شیردهی نخی یقه دار زنانه خالدار
- تیم والیبال کاراسونو
- تک تاک
- شرکت کالای صنعت نفت
- محصولات کیهان
- delsatecco.rozblog.com
- قفل دیجیتال
- فارسروید
- beroozha
- Rank2Game
- پویان اسکنر
- lilini
- تعمیر و فروش
- kiamehr85
- دانلود رایگان کتاب
- ویلم
- پچ لیگ برتر ایران
- تفریحی و دانلود
- کنترلی کردن درب آپارتمان
- فن کویل